マルチモーダルAIとは?
マルチモーダルAIとは?
2023/11/29

マルチモーダルAI
とは?
科学の目でみる、
社会が注目する本当の理由

マルチモーダルAIとは?
マルチモーダルAIとは、異なる種類の情報をまとめて扱うAIのことです。例えば、カメラで撮影した映像とマイクで録音した音という異なる種類の情報から1つのAIを学習させることで、映像の中に写っている人が何を話しているのかをより正確に推定できます。マルチモーダルAIの研究が発展すると、複合的な情報から判断が必要なアシスタントロボットが作られたり、もっと少ないコストでAIを作れるようになったりと、AIがさらに高度で身近な存在になるでしょう。
AIの発展は目覚ましく、情報を解析するだけでなくテキストや画像を生成するAIが登場し、いろいろな場面で使われるようになっています。特に最近注目されているのが、画像・音・テキストなど単一種類の情報から学習するのではなく、複数の種類の情報を一緒に学習して、より高度な情報処理を行う「マルチモーダルAI」です。マルチモーダルAIは、複合的に情報を処理できる強みを生かして防犯カメラや自動運転など複合的な情報から判断が必要なAIなど幅広く応用できます。マルチモーダルAIの特徴や、産総研で行われているマルチモーダルAI研究の現在地や今後の展望について、人工知能研究センター知的メディア処理研究チームの緒方淳と、社会知能研究チームの坂東宜昭に聞きました。
マルチモーダルAIとは
種類が異なる情報を1つのAIが学習する
マルチモーダルAI(multimodal AI)とは、異なる種類の情報をまとめて扱うAIのことです。例えば、画像、音声、テキストという異なる情報を組み合わせたり、お互いに関連付けたりして処理します。
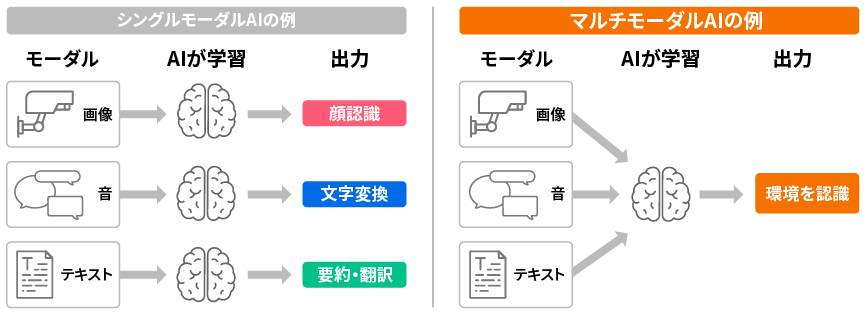 シングルモーダルAIとマルチモーダルAIの違い
シングルモーダルAIとマルチモーダルAIの違い
マルチモーダルAIの応用例としてわかりやすいのは、防犯カメラです。通常の防犯カメラは音の無い映像だけを記録するので、向かい合う2人が陽気におしゃべりをしているのか、言い争いをしているのかは細かい表情が分からなければ判断できません。ここに音に関係する情報を加えることで、話し声の内容やトーンから、より危険な場面なのかどうかをさらに精度高く判別できるようになります。
自動運転にも、マルチモーダルAIが応用できます。自動運転中は走行しながら障害物を検知する必要があります。カメラは物体が何かを判別することには優れていますが、暗所や逆光などに弱く、周囲の環境に強く影響を受けます。一方で、レーダーでは物体が何かを認識する精度は劣りますが、物体がそこに存在するかどうかの判別をする時には周囲の環境に影響を受けにくいのが強みです。カメラとレーダーの2つで得られた情報を組み合わせることで自動運転の物体判断の精度を上げることができます。
異なる種類のデータの間で関係性をつくる
マルチモーダルAIのなかでも、最近注目されているのが、「異なる種類の情報の間で共通する関係」に注目してAIに学習させるというものです。たとえば、楽器を演奏している人と演奏していない人を同時にカメラで映像を撮影し、マイクで録音した信号と一緒に学習させると「楽器を持っている人から音が聞こえる」という関係性を自動的につかめるようになります。このように、異なる種類の情報の間で同時に現れる特徴のことを「共起関係」といいます。映っている物体や聞こえる音が何かを人手で教示する「教師あり学習」より、両者の共起関係から自身で学習させるほうが、AIとしての性能を上げることができます。
映像と音から会話の方向を推定する
実際に、ロボットによる環境認識のために開発した「音が出ている方向を推定するAI」の事例で、映像と音の共起関係をつかったマルチモーダルAIの仕組みを詳しく見ていきましょう。
産総研では、展示物の間を動き回るロボットにカメラとマイクを搭載して、どこから音が出ているかを識別するAIを開発しました。映像から得られる音イベントの発生場所を予測した結果と、マイクからとった音データを組み合わせることで、実際にどこでいつ音が出ているかを推定します。カメラに写る人や展示物と、マイクで録音した会話や展示物の効果音、この2種の異なるデータを用いることで、機械の動作音や場内のアナウンスなど、いろいろな音の出る展示のある施設の中で、人手による教示を用いずに、展示物の物音や人の声がでている方向を示せます。人手で逐一「音を出す物体とは何か」を教えなくとも、学習データからその概念を自己教師的に獲得できる、自身で周囲の状況を理解し考え行動する自走式ロボットの開発につながる技術です。
 日本科学未来館(東京都)の中で、動き回るロボット。上部に設置された360度カメラから映像を、16個のマイクから音を取得しロボット周囲の環境を認識する。(Yoshiki Masuyama et al. 2020より引用*1)
日本科学未来館(東京都)の中で、動き回るロボット。上部に設置された360度カメラから映像を、16個のマイクから音を取得しロボット周囲の環境を認識する。(Yoshiki Masuyama et al. 2020より引用*1)
マルチモーダルAIの課題と今後の展開
ラベルをつけるコストは減るが、大量データの効率的処理が課題
一般的なAIモデルの学習においては、データすべてにそれが何なのかを示すラベル(教師情報)を付けて学習させる必要があります。このようなアノテーションと呼ばれるラベル付け作業には膨大なコストと手間がかかります。一方で、マルチモーダルAIのように異種のデータや複合的なデータを扱う学習では、教師情報がなくても、異なるデータから補完的に特徴を学習することなどにより、ラベル付けのコストを削減できると考えられます。
1種類のデータのみを扱うシングルモーダルAIと比べたときのマルチモーダルAIの難しさは、異なる種類のデータを扱うため、単純にデータ量が増えることです。データが増えると計算時間もかかるようになるので、データをより効率的に扱うための技術や、大規模なデータを扱える計算基盤が必要です。また、異なる種類のデータをどうやって補完的に取り扱うのかといった方法もまだ確立はされておらずさらなる研究開発が必要です。
さらに、マルチモーダルAIは、異なるさまざまな種類のデータから認識したり状況を解釈したりすることから、その判断根拠が利用者にわかりづらくなる面もあります。そこで、どのようにAIが判断したかという根拠を可視化して利用者に提示し「説明できるAI」に関する技術や機能が、一般的なシングルモーダルAIに比べてより重要になると考えられます。
自然言語処理技術と組み合わせてAIがより自然で身近に
マルチモーダルAIの研究や技術が発展すれば、AIはおそらく、人間の五感のように情報を解釈できるようになり、人間にとってより身近な、より自然な存在になっていくでしょう。
特に、ChatGPTに代表される自然言語処理技術を使った大規模言語モデルに注目しています。現在の対話型の大規模言語モデルは、テキストや画像を学習し出力するものを中心にだれもが利用できるようになっています。そこにマルチモーダルAIの技術をつかって、音声や動画のほかにもロボットの行動計画などさまざまな種類のデータを1つのニューラルネットワークで学習できるようになれば、物事を多面的にとらえ、より多様な出力のできるAIが実現すると考えています。(産総研マガジン「自然言語処理とは?」)
マルチモーダルAI技術によって、防犯カメラや自動運転だけでなく、より高度な提案ができるAIの開発が進むでしょう。産総研では、まずは音と画像のデータから環境音を認識するマルチモーダルAIを開発し、またそれを低コストで実現することを目指しています。世界中で、多様なモダリティ(modality)を混ぜた基盤的なAIの研究が活発に進んでいます。マルチモーダルAIの学習モデルを扱いやすいかたちにして提供するための知見を積み重ね、今後のさまざまな連携につなげていきたいと考えています。
*1: Yoshiki Masuyama, Yoshiaki Bando, Kohei Yatabe, Yoko Sasaki, Masaki Onishi, and Yasuhiro Oikawa. 2020. Self-supervised Neural Audio-Visual Sound Source Localization via Probabilistic Spatial Modeling. In 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE Press, 4848–4854. https://doi.org/10.1109/IROS45743.2020.9340938 [参照元へ戻る]