日本発、最高精度の画像認識AIを誰でも実現可能に!
日本発、最高精度の画像認識AIを誰でも実現可能に!

2022/11/30
日本発、最高精度の画像認識AIを誰でも実現可能に! 事前学習用データを数式により生成

 人工知能(AI)の性能を高めるためには、AIの学習対象となる大量のデータが必要となる。しかし、AIを実際に必要とする企業や工場、病院、流通拠点といった場所で集められるデータには限りがあり、AIの能力を十分に引き上げられない。このことがAI開発の現場を苦しめてきた。
人工知能(AI)の性能を高めるためには、AIの学習対象となる大量のデータが必要となる。しかし、AIを実際に必要とする企業や工場、病院、流通拠点といった場所で集められるデータには限りがあり、AIの能力を十分に引き上げられない。このことがAI開発の現場を苦しめてきた。
産総研は、画像を認識するAIの開発において、実物が写った画像、実画像の代わりに数式により生成した画像を用いてAIの事前学習を行うことで、現場で集めるデータが少なくてもAIが最高水準の精度を獲得できる技術を開発した。この技術を用いて獲得した大量の画像データや、事前学習済みのAIを無償で公開することで、日本の産業界のAI活用に貢献したいと企業や大学、研究機関に働きかけを行っている。
画像認識AIの事前学習に革新をもたらす
小さな町工場でも、世界最高性能のAIを開発できるようになる、そんな未来を期待させる技術が開発された。産総研人工知能研究センターの片岡裕雄たちが開発した数式による画像生成の技術である。
この技術が対象とするのは、撮影した画像に何が写っているかを判断する画像認識のAIである。AIの事前学習には大量の画像データを必要とするが、それらを実画像そのものに頼らず、数式により生成された画像を使ったにもかかわらず、条件によっては実画像をも超える画像認識精度を実現したことが、今回の技術の最大の特徴だ。生成されたデータを活用することができれば、経営資源が限られた小規模企業であっても、大量の実画像を収集せずに、世界のトップ企業とわたり合える、最高水準の画像認識AIを自ら開発できるようになる可能性を持っている。(2022/6/13プレスリリース記事)
技術の詳細を説明する前に、まずはその成果の概要を見てみよう。
AIの学習に使える大量の画像を集めたデータセットの代表例に「ImageNet-21K」がある。人や動物、自動車や建物など、約2万1000種類の事物が写った画像を、合計1400万枚以上も集めたもので、インターネットで公開され学術用に広く利用されている。片岡らのグループは、この「実画像データセット」を学習したAIと、自分たちが「フラクタル幾何」と「輪郭形状」という2種類の数式を用いて生成した画像を学習させたAIの三つの学習済みモデルで、画像認識の精度を比較検討した。その結果は実画像では81.8 %、フラクタル幾何で82.7 %、輪郭形状で82.4 %と、数式により生成したデータが実画像を上回る数値を示したのである。
その差は1 %に満たない数値であるが、AIを学んだ技術者や専門家からすれば驚きの数字であるという。「認識精度は、世界中の研究者が頑張って年間1 %上がるかどうかです」と片岡は言う。
 学習に「実画像」(ImageNet-21K)を使った場合よりも、今回の技術で開発した「フラクタル幾何による画像」や「輪郭形状による画像」を用いたほうが、画像認識AIの精度は高くなった
学習に「実画像」(ImageNet-21K)を使った場合よりも、今回の技術で開発した「フラクタル幾何による画像」や「輪郭形状による画像」を用いたほうが、画像認識AIの精度は高くなった
この画像認識率は、大変高いレベルといえるが、AIの研究開発でトップランナーといわれるグーグルが膨大な量の画像を学習させて得た世界最高精度にはまだ届いていない。グーグルは、すでに独自に集めた非公開のデータセットを使って84.15 %というさらに上の認識精度を実現しているのである。ただし、このモデルが学習に使った画像枚数は、実に3億枚と言われ片岡らが事前学習につかったデータセットの2100万(輪郭形状による画像)〜5000万枚(フラクタル幾何による画像)に比べ、学習に使ったデータが桁違いに多い。ちなみに、グーグルは現在、もう1桁多い30億枚の画像を使った研究を進めている。
片岡たちは、こういったIT大手企業のように力技で画像データセットを集めるのではなく、大量の実画像に頼らず、数式による生成によってAIが学習できる画像の量を増やして、彼らに匹敵する認識精度の達成を目指している。この研究は、国立研究開発法人新エネルギー・産業技術総合開発機構(NEDO)の開発プロジェクトの一環として進められており、目を見張る進展を見せている。
「プロジェクトが終了する2025年3月までには、約3億枚の実画像データで事前学習したモデルと同様の画像認識精度に到達できると思います」と片岡は、当初より数段回引き上げた高い目標の達成にも自信を見せる。
動物の視覚の仕組みから発想を得る
今回の技術で注目すべき点は、学習に使う画像データが“モノクロの抽象的な図形”からなることだ。上の図を見てわかるとおり、実物を写した写真(実画像)とは似ても似つかない。それはこの技術が、数式で表した規則に従って機械的に画像を生成するからだ。さらに、この技術は数式の形や係数を工夫することで、図形のバリエーションを増やすことができ、何千万枚もの画像が簡単に生成できるのである。
しかし、なぜ抽象的な図形を使って自然の事物を認識するAIの性能を高めることができるのか。その秘密はAIの学習方法にある。深層学習技術を使った最近のAIは、転移学習と呼ばれる手法を使って2段階で学習させることが多い。
まず、大量の汎用的なデータで基礎的な認識能力を養う学習(事前学習)、次に特定用途に絞り込んだ少量のデータによって再度学習させる(追加学習)、その二つのプロセスを経て、性能を高めていくのである。
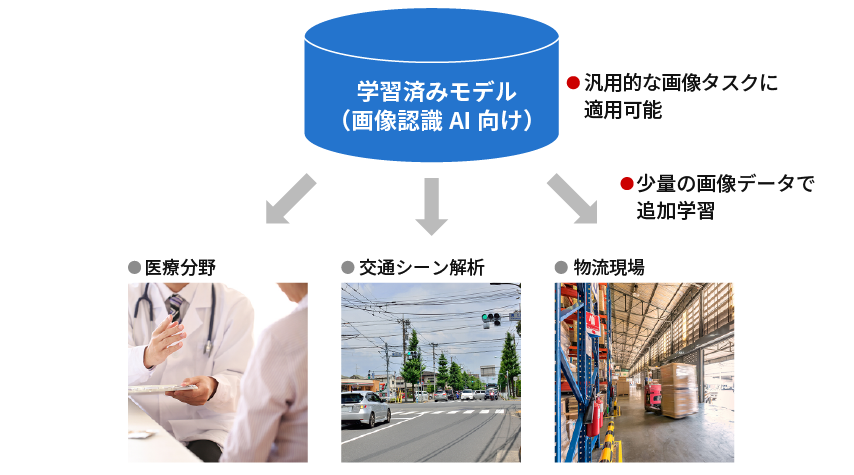 事前学習済みのAI(モデル)を医療分野など個別の用途のデータで追加学習させることで、高精度の画像認識AIを実現できる
事前学習済みのAI(モデル)を医療分野など個別の用途のデータで追加学習させることで、高精度の画像認識AIを実現できる
今回の技術は、この2段階の学習のうち「事前学習」に使われるものだ。ではなぜ、基礎的な認識能力を養う「事前学習」には、抽象的な図形をデータに使っても最終的に正しい結果を導き出せるのだろうか。
その理由は、人を含む動物の脳の仕組みや学習方法にある。動物の脳で視覚をつかさどる部位(一次視覚野)は、目から入ってきた画像の情報から、まずさまざまな方向の“線”を検出する。つまり、動物はどんな光景を見ても、最初は無数の線の組み合わせに分解して認識しているというわけだ。
この動物の認識能力は、遺伝子による決定ではなく、出生後の学習によって身につけられることがすでに知られている。実際に、生まれたばかりの猫を縦の線しかない環境で育てると、横方向の線が認識できなくなるとの研究もある。*1
これは、事物がその形のなかに持っている“多様な線の組み合わせ”を最初に学習しておかないと、動物は視覚に異常をきたすということを意味する。それは逆に言えば、“自然環境が備える線の組み合わせ”を十分に表現した幾何学的な図形があれば、実画像の代わりとして視覚能力の事前学習に活用できるというわけだ。これは、画像認識AIであっても同様である。
自然の中にある幾何学的性質を機械学習に取り込む
では、一体どんな図形を使えばAIを適切に学習させられるのか。
片岡は上司(当時)の佐藤雄隆と話すなかで、「フラクタル画像が有望ではないか」ということに気がついた。フラクタルとは日本語で「自己相似性」と呼ばれ、自然の風景や生物などにしばしば見られる幾何学的性質のことである。例えば、海岸線の形状や木の葉の葉脈のように、どんどん寸法を拡大して見ても、同様の形状がどこまでも現れてくる現象を指す。フラクタル性を持った図形は、数式での生成も容易である。
 自然の中にある自己相似性(フラクタル)のある植物や景色
自然の中にある自己相似性(フラクタル)のある植物や景色
動物の視覚がフラクタル性も持つ自然環境を的確に認識するように進化したとするなら、自然の特徴をしっかりと捉えたフラクタル画像を学習に使えばいいのではないか。そう考えた二人は、実画像を使ったAIに迫る性能が出せれば……と実験に取り組んだ。その結果は前述したとおり。本人たちの予想も超える画像認識率であった。
 フラクタル画像の例
フラクタル画像の例
自然環境の特徴をうまく反映した図形として、片岡らは輪郭形状による画像も試している。こちらは、画像認識AIで主流になりつつある最新アルゴリズム(ビジョントランスフォーマー)が、輪郭の情報を主な手掛かりにしているという知見をもとに行った実験だ。この結果も、先述のように、フラクタルと同等の高い数値であった。
 輪郭画像の例
輪郭画像の例
学習に使う画像データは“モノクロの抽象的な図形”であり、フラクタル幾何と輪郭形状どちらのデータセットも、色の情報は使っていない。色を変化させた画像データも試してみたが、精度を押し上げる効果がほとんどなかった。そのため、事前学習ではモノクロの画像を使い、色の情報は、追加学習で与えればよいと判断したわけである。
画像データ収集時の人為的なミスや権利侵害も防ぐ
数式から生成する図形の画像による恩恵は、大量の学習データの用意が誰でも可能になるということにとどまらない。
AIの学習に使う画像データは、何が写っているのかといった「正解」を記述した「ラベル(図形の種類を示す番号)」を、あらかじめ1枚1枚、人手で追加する必要がある。人間の判断が入るので、データが大量になれば誤りも紛れ込むことがある。また実際、過去に人種差別的な判断を下した画像認識AIの事例があったが、これは学習に用いた画像が特定の人種に偏っていたことが原因といわれている。AIは学習時に使ったデータとそのラベリング次第で思わぬ誤動作を引き起こすリスクがあるのだ。
加えて、学習後のAI内部の動作原理は、はっきりとはわからない「ブラックボックス」状態となる。したがって、AIが思わぬ動作を起こした場合、問題の原因となるデータの発見が困難になる。また、大量のデータを集める際に、他者のプライバシーや権利を侵害するデータが、知らずに紛れ込むリスクもある。*2
しかし、数式をもとに作成した図形データでは、これらの懸念は拭い去られる。人工的な図形なので、人間の偏見や間違いが入ることはない。人手をかけて付ける必要があったラベルもデータごとに自動的に付与することができる。
産総研は、今回作成したデータセットと学習済みのAIを、誰もが使えるようにオンラインで公開(プロジェクトのWEBサイト)している。実験の比較対象とした実画像データセット(ImageNet-21K)も公開されており、研究者にとってはなじみ深いが、用途が教育・研究用に限定されており、商用に使えないという難点があった。しかし、産総研が公開する情報は、企業の各種製品開発や有償サービスへの応用も可能である。
今回のデータセット公開は、あらゆる企業に最高水準の画像認識AIを作れる機会を提供することになり、競争の激しいこの分野では、世界的に見てもまれな取り組みといえる。すでに、ベンチャー企業のAIメディカルサービスが医療用画像認識システムの開発にこのデータセットを活用するなど、実製品の性能を高めるための動きが始まっている。
「日本には製造業を始めとして世界に負けない技術力があり、その現場には競争力のある貴重なAI学習データが存在しています。一方、データの数の面では様々な制約から十分に用意できないケースが多く、泣きどころとなっていました。このような少量ではあるが競争力のある学習データと、私たちのデータセットを組み合わせて使うことで、世界トップクラスの企業と勝負ができるAIが出来上がると期待しています」(佐藤)。

あらゆるAIに応用できる基盤となるモデルをつくる
片岡らが開発した技術の強みは、従来の問題点の解決だけにとどまらない。その展開可能性について見てみよう。
この技術のもう一つの大きな強みは、適用できるデータが2次元の静止画像だけにとどまらないことだ。例えば、最新のスマートフォンに組み込まれている、3次元の物体形状を計測するセンサが生成する画像データにも応用可能である。実際に、数式で3次元のフラクタル図形を作り出して事前学習に使い、現実の部屋の3次元データから、物体がある場所を検出するAIの開発に利用できることを確認している。
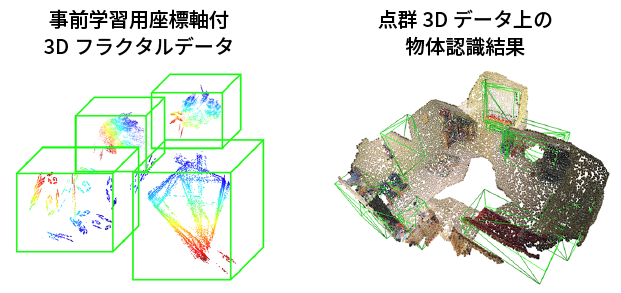 左側はAIの事前学習に使う3次元のフラクタルデータ。右側は屋内の3次元データから物体を検出した結果
左側はAIの事前学習に使う3次元のフラクタルデータ。右側は屋内の3次元データから物体を検出した結果
さらには静止画だけでなく、動画や音声といった、時間と共に刻々と変化するデータの活用も射程に入っている。人がランダムなパターンとして感じているデータを数式により生成し、事前学習に活用する方法を開発中で、動画についてはすでに、予備的な実験によって効果の高さを実証している。
片岡らが最終的に目指すのは、一つのAIでありながら、あらゆる応用に使い回せるAIのひな型を作ることにある。「汎用学習済みモデル」と呼ばれる、あらかじめ、静止画、動画、3次元データといった異なる種類のデータを事前学習させておき、追加学習で与えるデータ次第でさまざまな用途に展開できるAIが目標だ。
このような基盤となるAIモデルはグーグルやオープンAI、メタといったAI研究で知られる先進的な海外企業が開発にしのぎを削っている。2022年夏に一躍脚光を浴びた、言葉で表現した内容を即座にイラストにしてくれる「画像生成AI」は、基盤モデル研究の派生物だ。
産総研の狙いは、日本の産業界の競争力を底上げすることにある。片岡らをはじめ多くの研究者が日本発の汎用学習済みモデルの構築を進め、大学や企業などとタッグを組みながら、パーツとなり得る基礎技術を開発してきた。
「容易に構築・導入してもらえるAI、あらゆる応用に使い回せるAIの基盤をつくって、日本の産業を支えたい、国の研究機関としてぜひ貢献したいと考えています」片岡たちの研究はさらに広がっていく。
*1: C. Blakemore and G. F. Cooper, “Development of the Brain Depends on the Visual Environment,” Nature, vol. 228, Oct. 31, 1970.[参照元に戻る]
*2: 日本の著作権法第三十条の四によれば「著作権者の利益を不当に害する場合」を除けば、著作権者の許諾を得ずに著作物をAIの学習に使うことが可能である。[参照元に戻る]
情報・人間工学領域
人工知能研究センター
コンピュータビジョン研究チーム
主任研究員
片岡 裕雄
Kataoka Hirokatsu
情報・人間工学領域
研究企画室
研究企画室長
佐藤 雄隆
Satoh Yutaka