独立行政法人 産業技術総合研究所【理事長 吉川 弘之】(以下「産総研」という)情報技術研究部門【研究部門長 関口 智嗣】音声情報処理グループ【研究グループ長 児島 宏明】李 時旭 研究員は、マルチメディアコンテンツを音声により直接検索する技術を開発し、音声検索システムの実証サイト(http://www.voiser.jp)を公開する。
本システムは、インターネット上の動画サイト、音声サイトといったマルチメディアコンテンツに含まれる音声を直接検索対象とし、コンテンツ中のキーワードの検索を実現したもので、辞書を用いる必要がなく、どのような単語も無制限にキーワードとして使えるという特長を持つ。これを可能としたのが音声認識用に研究を進めてきた独自のユニバーサル符号化技術である。本システムでは音声を「音素片(SPS: Sub-Phonetic Segment)」と呼ぶ精細な単位に分解・符号化する。この符号化した音素片に対して独自の高速検索処理を行うことで、実用に耐える検索性能を達成した。これにより、新たな固有名詞や新語を含むインターネット上の大量のマルチメディアコンテンツを、メンテナンスなしにリアルタイムで検索対象にできる。本技術の実用化により、ユーザーが必要なマルチメディア情報を効率よく取り出すことが可能になり、これまで十分に利活用されてこなかった膨大なマルチメディアコンテンツに新たな価値を創出する可能性が拡がる。
本成果は、2008年10月20日~21日に産総研つくばセンターで開催される「産総研オープンラボ」で公開する予定である。(「音声による家電操作とマルチメディアコンテンツ検索」として研究室公開予定)
世界中に存在するテキスト情報、マルチメディア情報などのデータ量は爆発的に増大し、2007年末で約250エクサバイトに達したと言われている。中でも、インターネット上には膨大な情報が存在し、その中から必要な情報を検出し有効に活用するための分類・分析・検索技術の必要性が高まっている。テキストデータについては、商用の全文検索サービスが普及し、テキスト情報を活用する利便性は著しく高まった。
しかしながら、動画などのマルチメディアコンテンツについては、インターネットにおける動画配信サイトや家庭での大容量録画機器の普及により、その情報量が爆発的に増大しているにもかかわらず、そこからユーザーの求める情報を取り出そうとすると、現状では人手で付加したジャンルや要約などのタグ情報を頼りに検索するしかなく、効率的な検索が困難であった。このような課題に対応するために、マルチメディアコンテンツに含まれる音声から、その内容に基づいて検索を行う音声検索技術への関心が高まっている。
音声検索の手法としては、大語彙連続音声認識に基づいてテキストに変換した上で全文検索を行うのが一般的手法であるが、音声認識の際の誤認識や、認識用単語辞書に含まれない新語・未知語・固有名詞等への対応が問題となっている。それに対処する手段のひとつとして、産総研・情報技術研究部門では、インターネット上でユーザーの協力により語彙の追加や認識結果の修正を行う手法を用いる「PodCastle(ポッドキャッスル)」システムを発表した(2008年6月12日 プレス発表)。
一方、本研究では、大語彙音声認識の枠組ではなく、音を符号化した上でマッチングを行う手法を採用して辞書の問題を解決した。音を表現する符号としては、一般的に用いられる音素のようなローマ字表記相当の単位ではなく、より精密な単位として、1980年代から田中和世氏(現筑波大教授)を中心に独自に研究を進めてきた音素片に基づくユニバーサル符号を採用した。また、伊藤慶明氏(現岩手県立大准教授)との共同研究により、マッチングアルゴリズムの高速化を行ってきた。
今回、それらを統合して、一般的なブラウザーからアクセス可能な、実用に近いマルチメディア検索システムを構築した。
本研究では、音素よりも細かくかつ言語情報を保つ最小単位として考案されてきた音素片(SPS)に基づいて定義した「ユニバーサル符号系」を設計した。この最小単位をベースにすることで、検索処理の際に精度の劣化が抑えられ、辞書なしでの検索が可能となった。検索対象データベースと検索キーワードを、いずれもユニバーサル符号系に変換し、その符号間のマッチングを数値化して照合を行う。照合処理手法についても高速処理アルゴリズムを開発した。これらにより、単語登録を不要にした「語彙フリー」の検索システムを実現した。
また、従来の音声認識では辞書が不可欠であるため、処理対象の言語に強く依存していたが、ユニバーサル符号系は国際音声記号に基づいて音声学的に定義されているため、言語非依存の技術である。そのため、多言語化や方言などへも容易に適用できる。検索語の入力も従来のようにテキストだけではなく、声で入力することも可能である。この特長から、高齢者や障害者などのキーボード入力が難しい情報弱者でもアクセスしやすいマルチメディア情報サービスが可能となる。
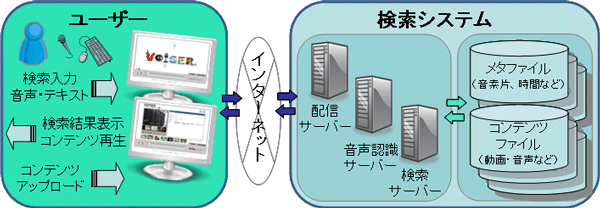
図1に本研究で開発した新しい手法の音声認識・検索技術を応用し、インターネット上でマルチメディアコンテンツの内容を検索可能とするために開発・公開するマルチメディア配信システムの構成を示した。
|
|
|
図1 インターネット上の動画・音声等を音声・テキストで検索するシステムの構成
|
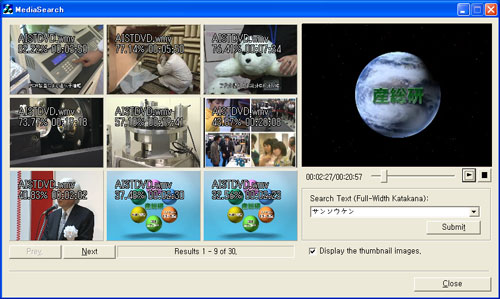
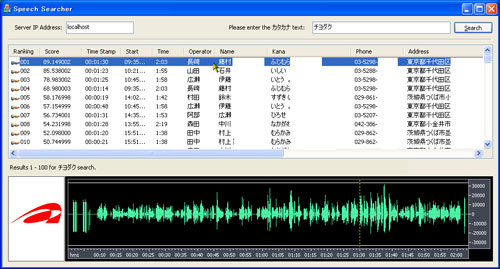
また、図2に音声検索技術の他の応用例として、左側の画面は産総研の広報ビデオを対象に発音レベルの検索語「サンソウケン」を入力して検索させた結果の画面である。検索結果の候補として、検索語が発声された時間に対応する動画を表示することにより、見たい場面を手軽に見つけられる。また、右側の画面は電話通話を録音した音声の中から任意のキーワードを入力することにより、キーワードが発声された通話をピンポイントで検索し、通話情報や音声波形を表示しながら音声を再生する画面である。実際に発声された声を検索して聞き直すことが可能なため、容易かつ正確に発言内容の確認を行える。
|
|
 |
|
図2 (上)マルチメディアコンテンツの中の音声を頼りに特定の場面を検出した例、
(下)通話録音データから特定の通話内容を検出した例
|
本技術の特長は次のように要約できる。
- 辞書を必要とせず未登録語問題を解決
- 容易に多言語に対応可能
- 方言・非母国語話者に対応可能
- 大語彙の辞書が不要であるため、システムがコンパクト
- 高齢者や障害者などの情報弱者でもアクセスしやすい
- 一般的なブラウザーから利用可能
これらの特長により、音声検索技術のメンテナンス問題を解決し、実用における汎用性を高め、広範囲への応用を可能にした。
今後は、ユーザーからの広範囲な試験利用を募ることで、有効性の検証と実用化のための改良を進める。また、実証システムの利用結果を活用し、本研究で開発された音声検索技術の改良を進めるとともに、従来のテキストベースの音声検索技術や、マルチメディア分類・要約等の技術との融合を進めて、より実用的なマルチメディア検索技術を開発する予定である。また、実証システムを通して、多方面からの評価用コンテンツの提供を受け、その情報を研究・開発にフィードバックすることにより、実用化を促進する計画である。
本技術により、インターネットや家庭での応用以外にも、コールセンターでの通話録音システムにおける音声検索機能や、大量のマルチメディアコンテンツを保有し、販売・配信する放送、教育など広範囲の応用が期待される。