東京科学大学(Science Tokyo)* 情報理工学院 情報工学系の岡崎直観教授と横田理央教授らの研究チームと国立研究開発法人 産業技術総合研究所(産総研)は、日本語能力に優れた大規模言語モデル(用語1)「Swallow」シリーズの最新版である「Llama 3.1 Swallow」を公開しました(公開リンク参照)。今回、80億パラメータ(用語2、8B)、700億パラメータ(70B)の規模に対し、それぞれベース(base)モデル(用語3)と指示チューニング(instruct)済みモデル(用語4)、合計4種類のモデルを公開しました。本モデルはLlama 3.1ライセンスで公開されているため、商用利用だけでなく、他のモデルの改良などにも利用できます。
Science Tokyoと産総研の研究チームは、英語の言語理解・生成や対話で高い能力を持つ大規模言語モデル(米Meta社 Llama 3.1)の能力をほぼ落とさずに、日本語の言語理解・生成や対話能力を高めることに成功しました。特に、80億パラメータのモデルは、同規模の既存の大規模言語モデルよりも高い日本語理解・生成能力を有することが確認されました。日本語と英語の両方において高い性能を達成するため、研究チームは学習に用いる日本語ウェブコーパスの大規模化・高品質化や、指示チューニングデータの自動生成などに取り組みました。
公開リンク:
https://swallow-llm.github.io/llama3.1-swallow.ja.html
*2024年10月1日に東京医科歯科大学と東京工業大学が統合し、東京科学大学(Science Tokyo)となりました。
Science Tokyoと産総研の研究チームは、高い言語理解・生成・対話能力を発揮する大規模言語モデルの構築方法やメカニズムを明らかにするため、日本語に強い大規模言語モデルを志向して研究開発に取り組んできました。研究チームが2023年12月に公開した大規模言語モデルSwallow、2024年3月に公開したSwallow-MSとSwallow-MX、2024年7月に公開したLlama 3 Swallowは多くのユーザからの支持を獲得し、学術研究やビジネスでの応用が進められています。同時に、国内外の研究機関・企業でもオープンな大規模言語モデルの開発が進展し、事前学習データのさらなる大規模化・高品質化、(自動生成された)合成データの活用、大規模言語モデル学習の効率化など、高い能力を発揮する大規模言語モデルの開発ノウハウが蓄積されるようになってきました。研究チームも、日本語の大規模ウェブコーパスの構築方法(参考文献1)、継続事前学習(用語5)による大規模言語モデルの日本語能力の強化方法(参考文献2)などを研究成果として発表しました。また、大規模言語モデルの開発の「レシピ」を探るため、研究チームで試作した大規模言語モデルの評価実験に加え、他の企業や研究機関で開発された大規模言語モデルの評価実験にも取り組み、その実験回数は2024年の4月~9月の6か月間で約400回にのぼりました。その実験結果の分析から、大規模言語モデルに日本語を教えたときに高められる能力の共通性を見出し、その知見を論文として発表しました(参考文献3)。今回、開発・公開された大規模言語モデルLlama 3.1 Swallowシリーズは、研究チームの最新の技術と知見の結集によるものです。
この取り組みのため、研究チームはAI橋渡しクラウド(ABCI: AI Bridging Cloud Infrastructure、図1)で実施している「大規模生成AI研究開発支援プログラム」から支援を受け、ABCIの一定部分(Aノードと呼ばれる高性能な計算ノード36台)を最大140日間占有利用する機会を得ました。また、モデルの学習データとして、東京工業大学(現・東京科学大学)が国立研究開発法人新エネルギー・産業技術総合開発機構(NEDO)のプロジェクトで開発した大規模な日本語ウェブコーパス(研究成果1を参照)を用いました。

図1 産総研 AI橋渡しクラウドABCI
1. 日本語のウェブコーパスの大規模化および高品質化
研究チームでは、Common Crawl(用語6)から配布されているアーカイブ全量(2013年から2023年に収集された94スナップショット、約2547億ページ)から日本語のテキストを独自に抽出・精錬した日本語ウェブコーパス(Swallow Corpus Version 2)を構築しました。この規模は、これまでのSwallowモデルの構築に用いられたSwallow Corpus Version 1(参考文献1)の約4倍にあたります(コーパス構築時に対象としたウェブページの総数の比較による)。また、大規模言語モデルの学習に適しているウェブページを厳選してから重複除去(用語7)を行う方がコーパスの精錬処理を軽くできますが、Swallow Corpus Version 2ではウェブページの厳選方法を後から試行錯誤できるように、この処理フローを逆順に変更しました。この順番でコーパス構築を行うと、必要な処理時間と記憶容量が増えるため重複除去が難しくなりますが、約1か月かけて日本語の全ページ対を対象とした重複除去を行いました。重複除去後の日本語ウェブページの規模は、3.2兆文字(19億ページ)でした。
Swallow Corpus Version 1では、平仮名の割合や文字数などのヒューリスティック・ルールによりウェブページの厳選を行っていました。Llama 3.1 Swallowのモデル構築では、これらのルールの有用性を検証し、大規模言語モデルの学習に適しているものだけを選別しました。また、ウィキペディアの記事は大規模言語モデルに対する「教育的価値」が高いと見なし、ウェブページの教育的価値を自動的に推定する分類器を機械学習で構築しました。これらの基準で厳選されたテキストデータと、数学やコーディングなどのデータを混ぜて、約2000億トークンからなる学習データを構成し、Llama 3.1 Swallowの継続事前学習に用いました。図2に示すように、Llama 3.1 Swallow 8Bの日本語理解・生成タスク(質問応答、翻訳、要約、算数、一般教養問題、コード生成などの10タスク)の平均スコアは0.4905となり、前バージョンのLlama 3 Swallow 8Bの平均スコア(0.4717)から約2ポイント上昇し、オープンな8B以下の大規模言語モデルの中では最高性能を達成しました(2024年10月現在)。
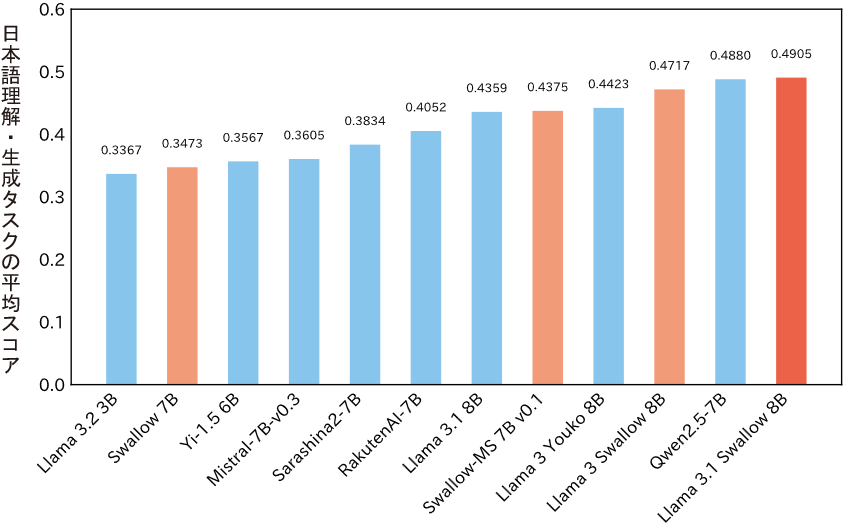
図2 主要なベースモデルの日本語理解・生成タスクの平均スコア(8B以下)
2. 合成データによる対話能力の向上
大規模言語モデルの対話能力を向上させる鍵は、多様かつ複雑な指示、および有用かつ流暢な応答からなる学習データで指示チューニングをすることにあります。理想的には、大規模言語モデルに寄せられる問いかけのデータを収集し、適切な応答を人手で付与したデータを構築することが望ましいですが、これには膨大な時間と労力が必要です。研究チームは、短期間かつ安価に学習データを構築するため、高い対話能力を有する既存の大規模言語モデルの応答を模倣するアプローチを採用しました。具体的には、人間と大規模言語モデルの対話履歴を収録したLMSYS-Chat-1Mデータセットの指示文を邦訳し、オープンなモデルの中でトップクラスの対話能力を有するLlama 3.1 405B Instructを用いて応答文を自動生成しました。また、Llama 3.1構築の方法論に倣い、複数の応答文を生成してからLlama 3.1 70B Instructに選好を自動採点させ、最良の応答文を選択するという工夫を取り入れました。さらに、重複する指示文や機械的な指示文、無用な繰り返しを含む応答を検出・削除することで、データの品質を向上させました。
上述の方法で構築した独自の合成データに加えて既存のデータも併用し、Llama 3.1 Swallowの指示チューニングを実施しました。その結果、対話能力を測定する日本語MT-Benchにおいて、Llama 3.1 Swallow 8B Instructは Llama 3 Swallow 8B Instructと比べて平均スコアを約5.6ポイント(0.4766から0.5327に)改善し、8B以下の大規模言語モデルではトップクラスの対話性能を達成しました(図3)。また、Llama 3 Swallow Instructは英語・英語混じりの応答を返しやすい問題があリましたが、模倣先を Llama 3.1 405B に変更し、自動生成データに含まれる日本語の割合を精査したことで、多くの応答を日本語で返すようになりました。
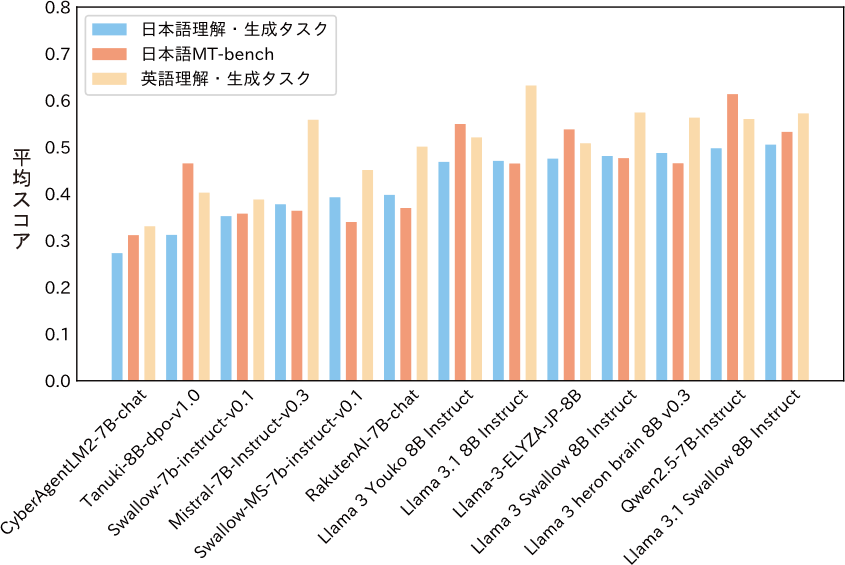
図3 主要な指示チューニングモデルの性能(8B以下、日本語理解・生成タスクのスコア順)
3. 継続事前学習における英語での能力の維持
継続事前学習で大規模言語モデルの日本語能力を強化すると、大規模言語モデルが元々持っていた能力(主に英語の言語理解・生成能力)が低下する傾向が観測されます。例えば、Llama 2 7BからSwallow 7Bへの継続事前学習では英語の言語理解・生成タスクの平均スコアが6.1ポイント低下、Llama 2 70BからSwallow 70Bでは2.7ポイント低下しています。大規模言語モデルに日本語を教えるには、英語での能力低下を想定しておく必要がありますが、算術推論、一般教養、コード生成などのタスクに関しては、英語で習得した能力が日本語に転移しやすいので、元の能力を維持することが望ましいです(参考文献2)。
Llama 3.1 Swallowの開発を進めるにあたり、一般教養タスクとコード生成タスクの性能を改善するための学習データの選別を行いました。その結果、一般教養タスクで効果を示したDataComp-baseline、コード生成タスクで効果を示したThe Stack v2などのデータセットを採用することに決定しました。さらに、予備実験で最適なデータセットの配合を探索したところ、Llama 3.1 8BからLlama 3.1 Swallow 8Bへの継続事前学習では英語の言語理解・生成タスクの平均スコアが0.6ポイントの低下に留まり、Llama 3.1 70BからLlama 3.1 Swallow 70Bへは逆に1.4ポイントの向上が得られました。図4に、Swallow 7BおよびLlama 3.1 Swallow 8Bの継続事前学習前後における英語の言語理解・生成タスクのスコアをレーダーチャートで示しました。Swallow 7Bでは各タスクのスコアの低下が目立つのに対し、Llama 3.1 Swallow 8Bではスコアの低下が抑えられています。このようなデータセットの取捨選択・配合に関する知見は、日本語と英語の両方に強い大規模言語モデルの構築方法を探るうえで重要な成果です。
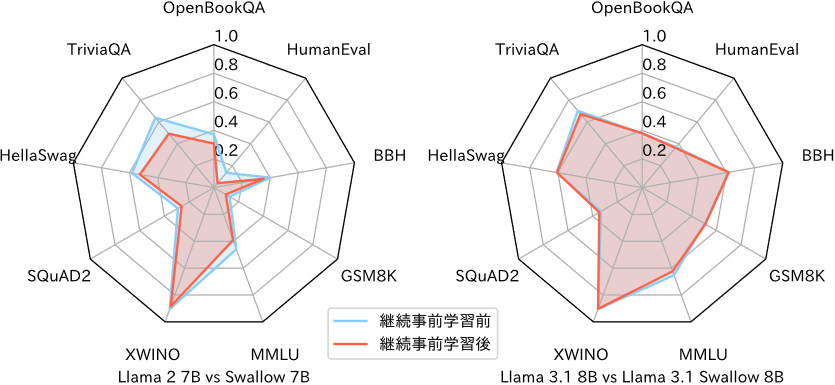
図4 継続事前学習の前後での英語の言語理解・生成タスクのスコアの変化
(左側は初代Swallow、右側はLlama 3.1 Swallow)
4. 分散並列学習における処理速度の向上
大規模言語モデルの学習では、多数のGPUを用いた分散並列学習が用いられます。利用するGPU数を増やすことで、モデル学習の全体としての処理速度は速くなりますが、GPU間の通信がボトルネックとなるため、1GPUあたりの処理速度(計算効率)が低下する傾向にあります。そこで、計算と通信をきめ細やかに織り交ぜることで、計算効率の低下を抑える工夫を導入しました。これに加えて、分散並列学習の設定を再検討し、Llama 3.1 Swallowを学習する上で最適な設定を探索しました。図5に、Llama 3.1 Swallowの継続事前学習における1GPUあたりの処理速度(TFLOP/s、用語8)、すなわち計算効率を示しました。図5が示すように、マイクロバッチサイズ=2(用語9)の設定では、128GPU(16ノード)で大規模言語モデルを学習する際でも、8GPU(1ノード)で学習する場合と同等以上の計算効率(184.9 TFLOP/s)を達成できることを確認しました。
また、GPU数が増加すると意図せぬ形で学習が停止することがあり、これが大規模言語モデルの学習効率低下の要因となることがありました。Llama 3.1 Swallowの継続事前学習では、通信に関する設定を調整することで、途中で意図せずに学習が止まるケースを大幅に削減し、計算資源の利用効率を高めることに成功しました。
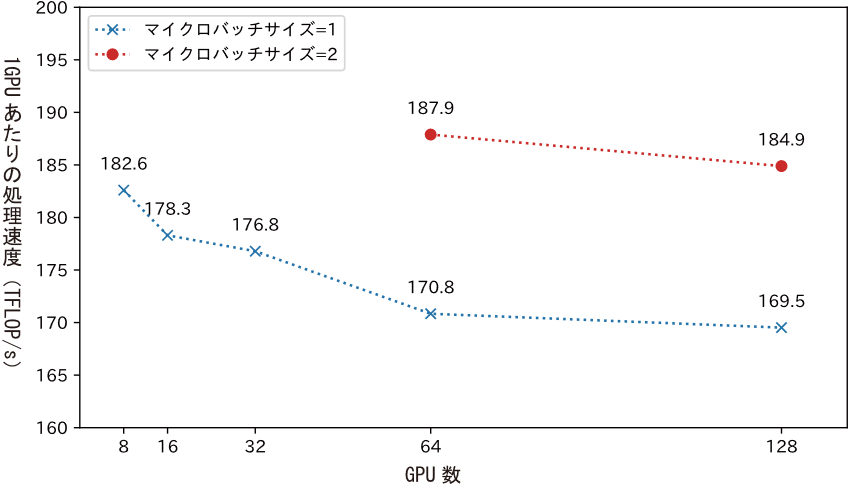
図5 ABCI A100 (40 GB) においてGPU数を増やした時の計算効率
公開された大規模言語モデルは学術と産業の両方に恩恵をもたらすと考えられます。自然言語処理や人工知能分野で新たな研究成果が生み出される他、信頼できる人工知能の実現に向けた研究開発が促進されます。産業分野では、APIの使用などで外部の企業に依存することなく、自社で大規模言語モデルを運用できるだけでなく、特定のタスクに特化したモデルにチューニングができます。日本語と英語に強くオープンな大規模言語モデルが登場したことで、日本における大規模言語モデルの研究開発・活用がさらに促進され、製品開発や技術革新が進むと考えます。
産総研政策予算プロジェクト「フィジカル領域の生成AI基盤モデルに関する研究開発」、国立研究開発法人新エネルギー・産業技術総合開発機構(NEDO)の「次世代人工知能・ロボットの中核となるインテグレート技術開発」プロジェクト(JPNP18002)の「熟練者観点に基づき、設計リスク評価業務における判断支援を行う人工知能適用技術の開発」、文部科学省の補助事業「生成AIモデルの透明性・信頼性の確保に向けた研究開発拠点形成」、その他の支援によって実施されました。
[1] Naoaki Okazaki, Kakeru Hattori, Hirai Shota, Hiroki Iida, Masanari Ohi, Kazuki Fujii, Taishi Nakamura, Mengsay Loem, Rio Yokota, and Sakae Mizuki. Building a Large Japanese Web Corpus for Large Language Models. In Proceedings of the First Conference on Language Modeling (COLM), October 2024.
[2] Kazuki Fujii, Taishi Nakamura, Mengsay Loem, Hiroki Iida, Masanari Ohi, Kakeru Hattori, Hirai Shota, Sakae Mizuki, Rio Yokota, and Naoaki Okazaki. Continual Pre-Training for Cross-Lingual LLM Adaptation: Enhancing Japanese Language Capabilities. In Proceedings of the First Conference on Language Modeling (COLM), October 2024.
[3] 齋藤 幸史郎, 水木 栄, 大井 聖也, 中村 泰士, 塩谷 泰平, 前田 航希, Ma Youmi, 服部 翔, 藤井 一喜, 岡本 拓己, 石田 茂樹, 高村 大也, 横田 理央, 岡崎 直観. LLMに日本語テキストを学習させる意義. 情報処理学会 第261回自然言語処理研究会 研究報告 (2024-NL-261), 12, pp. 1–15, 2024年9月. (優秀研究賞)