NEDOの委託事業「人と共に進化する次世代人工知能に関する技術開発事業」(以下、本事業)で産業技術総合研究所(産総研)は、数理モデルから自動で学習できる画像認識AIの開発に取り組んでおり、今般、画像中の物体を認識する画像識別に加えて、物体の範囲情報など画像中の詳細内容を把握できる画像領域分割を行うAIの学習に成功し、画像領域分割を含む基礎的な視覚に関する能力を持つAIを実現しました。
今回実現した画像領域分割は、自動運転やロボットの視覚情報など産業応用で求められるコア技術です。従来、画像領域分割AIを学習させるためには、大量の実画像の収集や、人間が画像内の画素ごとに教師ラベルをつける作業など膨大な人的コストと、収集された実画像によって引き起こされる権利侵害や倫理問題がありましたが、本成果はこれらを解消しています。また、学習する元画像自体が数理モデルによるものであるため、産業応用時に柔軟なカスタマイズができます。
なお、産総研は本技術の詳細を、2023年10月2日から6日までフランス・パリで開催される国際会議ICCVで発表します。

図1 数理モデルから自動生成したデータセットによる画像認識AIの構築
現在、世界的にAIの産業応用が本格化しています。中でも、自動運転時のシーン認識やロボットが物体を把持する際など、画像認識AIを社会実装するにあたっては、画像中の物体を認識する画像識別だけではなく、物体の位置情報を含む画像中の詳細内容を把握できる画像領域分割※1がコア技術になるとして注目されています。
一方で画像領域分割は、大量の実画像に人間が手作業で教師ラベル※2を付与することで画像データセットを構成し、AIが学習することで視覚能力を獲得しますが、人間による教師ラベル付けには1画像あたり数十分の時間を要するとも言われています。また、産業現場によっては必要な画像の収集自体も難しく、膨大な人的コストを要します。このため、できるかぎり少ない画像で産業現場に適応可能な技術が求められています。さらに、現在、研究現場で使用されている画像認識AIは、学習した画像データセットの実画像によってプライバシーの侵害や、攻撃的ラベルを含むなど倫理面での問題が生じる懸念もあり、商用目的での利用が困難です。
こうした課題を解決するため、NEDO(国立研究開発法人新エネルギー・産業技術総合開発機構)の本事業※3において、国立研究開発法人産業技術総合研究所(産総研)は、数理モデル※4から画像や教師ラベルを生成することで、AIが基礎的な視覚特徴を自動で獲得する学習済みモデル※5の構築に取り組んでいます。学習済みモデルにより、その後の産業応用で個別に必要な学習の精度を底上げし、これまでよりも容易なAI開発を目指しています。
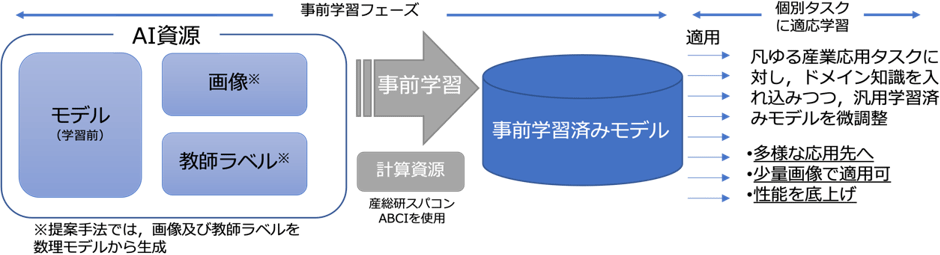
図2 画像認識AIの事前学習と適応学習
(1)画像認識AIモデルの構築
本事業では、数理モデルで生成した学習用の画像に、画像を識別した教師ラベルまで自動で生成するタスクまで成功※6しています。今回、より産業応用に特化したタスクとして、画素ごとの位置情報を生成できる画像領域分割のタスクを同時に学習できるようになりました。これにより、膨大な人的コストを抑えるとともに、実画像データを使用することなく、画像領域分割の事前学習モデルを構築できます。
画像領域分割技術を実現したことで、産業応用先のタスクに応じて画像や教師ラベルを柔軟に変化できます。加えて、画像、教師ラベルともに数理モデルから生成し、画像データセットを構築可能な性質上、プライバシー保護など倫理問題を気にせず容易にAIを構築できます。
(2)従来技術との比較
図3は、今回実現した数理モデルから生成した画像領域分割のデータセット(図3 1段目)と、AIが実画像と人がつけた教師ラベルで学習した従来の標準的な画像領域分割の公開データセット(図3 2段目「Cityscapes」、3段目「COCO-Stuff」)の例です。このように、従来のデータセットと同様に物体の種類ごとに領域を色分けした教師データを生成できることがわかります。

図3 画像認識AIが学習する領域分割の画像と教師ラベルの例
教師ラベルの画像(現画像の右側)は色の違いが意味の違いを示している。例えば、道路画像における路面や自動車など。
(3)産業応用時の多様なタスクに適応できる柔軟性
今回実現した画像領域分割のデータセットは、元となる数理モデルを柔軟に変更できるため、適応する産業現場で求められるデータの性質に合わせて、学習データにおける形状やテクスチャ、色などの見た目をパラメータで変更できます。画像領域分割データセットの構成要素を変化させることで、事前学習データセットの性質が変化し、どのような画像の領域分割が得意なのかが異なってきます。多様な画像領域分割データセットのタスクに応じてパラメータをあらかじめカスタマイズすることで、最も性能向上につながる事前学習を実行できます。
図4は今回実現した数理モデルによる画像領域分割データセットの構成要素を変化させた図であり、(a)1画像に載せる多角形の数、(b)マスクの種類、(c)色情報、(d)オクルージョン(重なり度合い)、(e)線の数(一つの多角形あたりの線の数)、(f)多角形の種類を示します。産業応用における多様なタスクに応じてこれらのパラメータをカスタマイズすることが可能です。
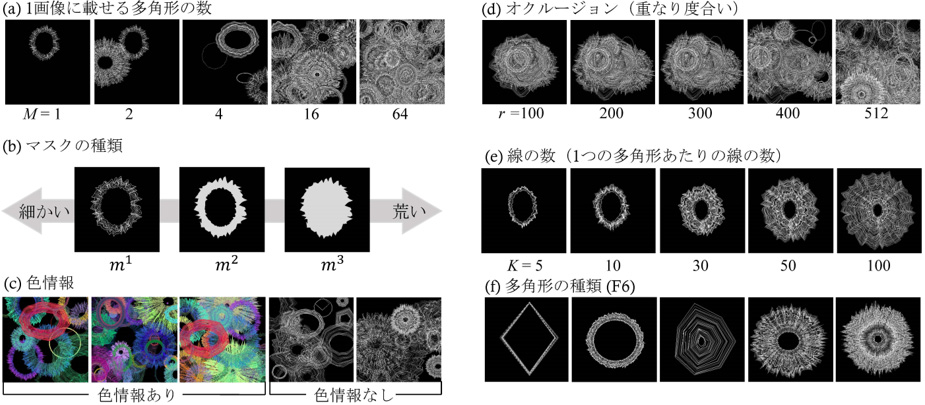
図4 データセットの構成要素
産総研は本技術の詳細を、2023年10月2日から6日にフランス・パリで開催される国際会議ICCVで発表※7します。今後は、人間の膨大な量の教師ラベル付けにコストを要する画像領域分割に対して本成果を適用していきます。
また、本成果のように、位置情報など高度かつ膨大な時間を要する領域分割を含む教師ラベル付けは、AI分野の至るところで開発のボトルネックになっています。数理モデルによる学習用の実データと教師ラベルの生成においては、あらゆる産業応用に耐えうるモダリティ(画像・動画・3Dなどデータ種別)やタスク(物体検出・領域分割・超解像など)の設定が根幹技術となります。将来的には、これらに対応するAIの「汎用学習済みモデル」を開発していく予定です。