NEDOと産業技術総合研究所は、実世界のデータを活用する次世代人工知能(AI)技術のソフトウェアモジュール構築の一環として、AIによる動画認識とバイオ分野に関する自然言語テキストの理解のための転移学習の基盤となる事前学習済みモデルを構築し、本日公開しました。
今回構築した事前学習済みモデルには、実世界の大量の動画やテキストデータをあらかじめ学習させているため、AI開発に用いることで、少量の学習用データでも次世代AIのソフトウェアモジュールを構築・利用できるようになります。これにより、例えば少量の動画データによる医療動画診断支援向けAIなど、実世界のデータを活用する次世代AI技術の開発と社会実装の促進が期待できます。
NEDOと産総研は、今後も各要素技術の性能を高める研究開発を継続するとともに、新たな要素技術のモジュールを開発し、公開していきます。
 |
|
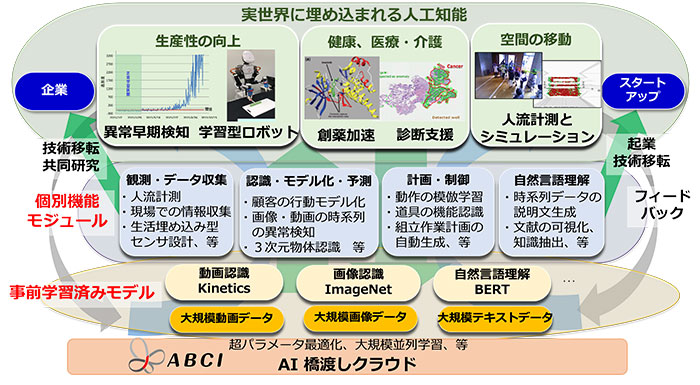
図1 次世代人工知能中核技術の研究開発の概要と、事前学習済みモデルの位置づけ |
インターネット上の各種サービスを通じて収集される大規模なデータに、深層学習などの機械学習技術を適用する高度な人工知能(AI)技術は、今後、IoTやロボットなどの技術と組み合わせることで、実世界のデータを用いたサービスにも適用され、超スマート社会を実現することが期待されています。
国立研究開発法人新エネルギー・産業技術総合開発機構(NEDO)は2015年7月より「次世代人工知能・ロボット中核技術開発プロジェクト」を開始し、先進的なAIの中核技術の研究開発を実施してきました。その中で、国立研究開発法人産業技術総合研究所(産総研)は、次世代AI技術分野の中核拠点として研究開発プロジェクト※1を受託し、大学や企業と連携しつつ、実世界で人間と相互理解して協働するAIの要素機能の研究開発を行い、開発したAIの要素機能を使いやすい形のプログラムに実装したソフトウェアモジュールを構築・公開してきました。
今回はその成果の一環として、新たに、AIによる動画の認識と自然言語テキストの理解のための転移学習※2の基盤となる事前学習済みモデル※3を構築し、本日公開しました。
今回構築した事前学習済みモデルには、実世界の大量の動画やテキストデータをあらかじめ学習させているため、AI開発に用いることで、少量の学習用データでも次世代AIのソフトウェアモジュールを構築・利用できるようになります。利用にあたっては、産総研人工知能研究センターのウェブサイト(https://www.airc.aist.go.jp/achievements/ja/)に掲示された公開用ウェブページからモデルをダウンロードして、特定応用のデータで追加的な学習を行います。深層学習の知識があれば利用可能です(利用要領やライセンスについてはそれぞれのウェブページをご覧ください)。これにより、例えば少量の動画データによる医療動画診断支援向けAIなど、実世界のデータを活用する次世代AI技術の開発と社会実装の促進が期待できます。
NEDOと産総研は、今後も各要素技術の性能を高める研究開発を継続するとともに、新たな要素技術のモジュールを開発し、順次公開していきます。
【1】事前学習済みモデルの構築・公開体制の整備
深層学習などの機械学習技術で高い性能を実現するには、質の良い学習用データで大規模に学習させる必要があります。しかしながら、実世界でデータを収集するにはセンサーの設置やネットワークの構築などのコストがかかるため、大規模なデータ収集は容易ではありません。また、まれな病気に対する医療データなどのように、絶対的に量が少ないデータも数多くあります。
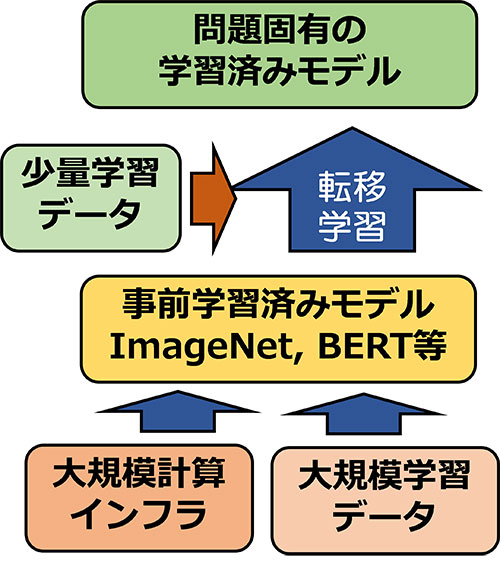
そこで、少量のデータを活用して高い性能を実現する方法として、収集しやすい一般的なデータで汎用的に使える事前学習済みモデルを構築し、そこに収集した少量の学習用データを用いて学習させる転移学習の枠組みが重要になっています(図2)。転移学習の基盤となる事前学習済みモデルとしては、例えば、静止画像の認識については、スタンフォード大学やプリンストン大学の研究者らが中心になって構築した「ImageNet」(http://www.image-net.org/)という1400万枚を超える大規模な画像データセット(の一部)で学習させたモデルがよく用いられています。
 |
|
図2 事前学習済みモデルとそれを用いた転移学習の仕組み |
こうした事前学習済みモデルの構築には、質の良い大量の学習用データに加え、それを処理するための大規模な計算資源が必要です。そのため、実質的には一部の巨大IT企業だけが事前学習済みモデルを構築できる状況であり、大学の研究者など大規模な計算資源を持たないユーザーが少量のデータを活用して高い性能を実現するためには、公開されている既存の事前学習済みモデルを利用する必要があります。
そこで、今回新たに、産総研が持つAI用クラウド計算基盤「ABCI」を活用した大規模な機械学習によって、さまざまな事前学習済みモデルを構築して公開できる体制を整えました。これらのモデルを転移学習の基盤として利用することで、少量のデータからでも、医用動画の認識やテキストの意味解析など、さまざまな個別課題の解決のための高性能なモデルの構築が可能になることが期待されます。
【2】動画の認識と自然言語テキストの理解のための事前学習済みモデル
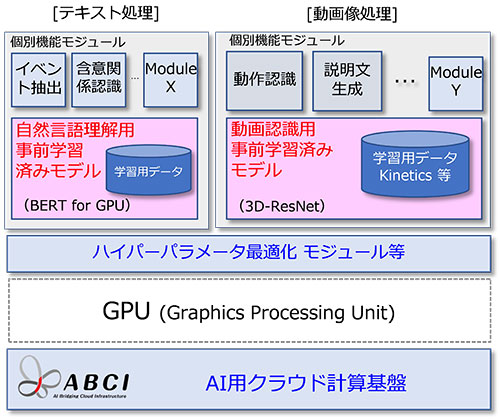
今回構築、公開したのは動画理解と自然言語理解のための事前学習済みモデルです(図3)。
動画理解のための転移学習の基盤となる事前学習済みモデルは、お茶を淹れる、絵を描く、ジョギングする、などの日常行動400種類に関する30万本のラベルつきの短い動画(Google DeepMind社のKinetics400データセット)を使って学習させたものです。このモデルを使うことで人の日常生活やスポーツの中の行動を識別することができます。さらに、このモデルをベースとして、個別の環境で収集された少量の学習用データを使って転移学習を行うことで、工場などの現場での作業のモニタリングや、作業支援をするロボットなどへの応用が期待できます。
自然言語理解のための事前学習済みモデルとしては、BERT※4やERNIE※5などがありますが、今回、世界で初めて、ニーズの高いバイオ分野に特化したBERTをバイオ分野の大規模テキストデータを使って最初から構築して公開しました。自然言語のテキストはそれが表現している分野、トピックによって出現する単語やその分布が異なっているため、こうした分野特化型の事前学習済みモデルの有効性が高いと考えられ、バイオ分野の科学技術文献から重要なイベントに関する情報(たとえば酵素反応などに関する情報)を抽出する性能などを高めることができます。さらに、ABCI上で BERT を学習させるためのプログラムも併せて公開しており、学習用データを用意することで、分野特化型の BERT を容易に構築できるようにしています。
 |
|
図3 自然言語テキスト処理、動画像処理向けの事前学習済みモデルとその応用 |
今回開発した事前学習済みモデルに加えて、混雑した環境での人流計測や物体の種類と姿勢の同時認識、道具の機能認識など、先進的な要素機能を実現する40余りのソフトウェアモジュールと機械学習用データセットを、産総研人工知能研究センターのウェブサイト(https://www.airc.aist.go.jp/achievements/ja/)で公開しています。今後も、新たな要素技術のモジュール開発とともに、各要素技術の性能を高める研究を進めます。さらに、大学や民間企業との共同研究などを通じて、開発したモジュールを個別ニーズに合わせてチューニングし、実用化することを目指します。