アンケート調査のなかで、性別や学年などのデータは機械的な処理がしやすい一方、自由記述形式で回答された意見は、機械的に処理することが難しく、大規模なアンケートの実施が困難であった。国立研究開発法人 産業技術総合研究所(以下「産総研」)人工知能研究センターの川本 達郎 研究員は、テクニカルスタッフの山下 慧、高橋 碧と共同で、機械学習を用いて大規模な自由記述の回答文から効率的に意見を集約できるアンケート手法「投票クラスタリング」(英語名: voteclustering)のシステムを開発し、実証実験の受付ウェブサイト(図1)を公開した。
なお、投票クラスタリングの手法は、川本研究員と国立大学法人 香川大学教育学部の青木 高明 准教授が共同で開発したものであり、その詳細は、2019年7月9日にSpringer Natureから出版されている機械学習分野の科学誌Nature Machine Intelligenceに掲載された(DOI: 10.1038/s42256-019-0071-y, SharedIt: https://rdcu.be/bJpUy)。
世論調査を始めとして、人々の意見を集約するアンケート調査は、頻繁に使われている重要な手段である。しかし、従来のアンケート調査は根本的な問題を抱えていた。選択式アンケートは、あらかじめ用意された回答候補に回答者が賛成・反対を表明するもので、回答者たちが真に心の中に思っていることが回答候補に含まれていない場合、不正確な結論を導いてしまうという問題がある。一方、回答者に自由に文章で回答することを許容する自由記述式アンケートは、回答を収集した後に、大量の意見の集約を行うことが非常に難しかった。自然言語処理技術を用いる処理方法もあるが、対象分野に関する辞書や多くの例文データを必要とする、正しく意味をくみ取ることが保証されない、といった問題がある。そのため、大規模で多様な意見を的確に収集・集計するアンケート調査は、現実的には大変困難であった。
人工知能研究センターの確率モデリング研究チームでは、日常生活の中の現象を購買行動データ、カメラなどのセンサーデータ、アンケートなどを通して観測し、確率的にモデリングし、シミュレーションや予測により、小売りや接客などのさまざまなサービスを改善することを目指した研究開発を行ってきた。その一環として、日常生活における価値観や意見を観測するための重要な手段の一つである、大規模な自由記述形式アンケート手法の研究開発と社会実装に取り組んできた。
なお、今回のシステム開発は、国立研究開発法人 新エネルギー・産業技術総合開発機構の委託業務「次世代人工知能・ロボット中核技術開発/次世代人工知能技術分野/人間と相互理解できる次世代人工知能技術の研究開発」の成果である。
投票クラスタリングの主な特徴は以下の通りである。
1. 従来通りのアンケート作成手順で、従来より容易に意見を集約
アンケート実施者は、アンケート作成時に「アンケート設定システム」(図2)にて、質問内容やいくつかの回答候補を登録する。作成方法は従来の選択式アンケートと近いため従来方法に慣れた実施者も気軽に利用を開始できる。さらに、当初選択肢にない回答が回答者によって候補に追加されていくため、実施者が選択肢を熟考する手間を省ける。アンケートを進める中で、提示される回答候補は動的に変わるため、初期選択肢が支配的な影響を与えることがない。
また、従来の自由記述式アンケートでは、分析者がすべての回答を読んで意味を判別する必要があったが、今回開発したシステムにより、アンケートの結果が解釈可能なものである限り、少数の代表的な回答を読むだけで、分類された意見からその意味を読み解くことが可能になる。
2. 自由記述の煩雑さを省きながら気づきを促す回答手順
アンケートシステムは、回答者に対して、ランダムに抽出された他の回答者の回答を一定数提示する。各回答者はそれらの回答に対して、自分の意見に合致するか否かを回答し、もしも自分の意見が提示された回答にない場合には、自身の回答を自由記述する(図3)。回答者の手順としては、通常のアンケートとなんら変わりがない上に、自分の意見に類似する回答候補も見いだせるようになる。投票クラスタリングは、アンケート中に他人の意見を参照させることが大きな特徴であり、回答者により深く考えさせ、多様な意見を抽出することにつながる。
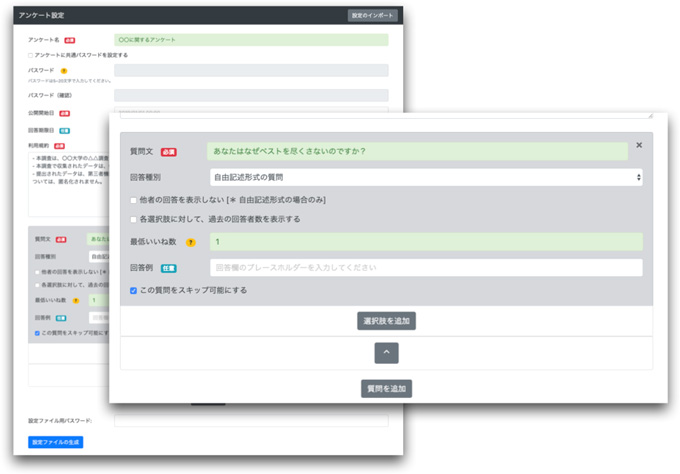 |
| 図2:アンケート設定システムの画面 |
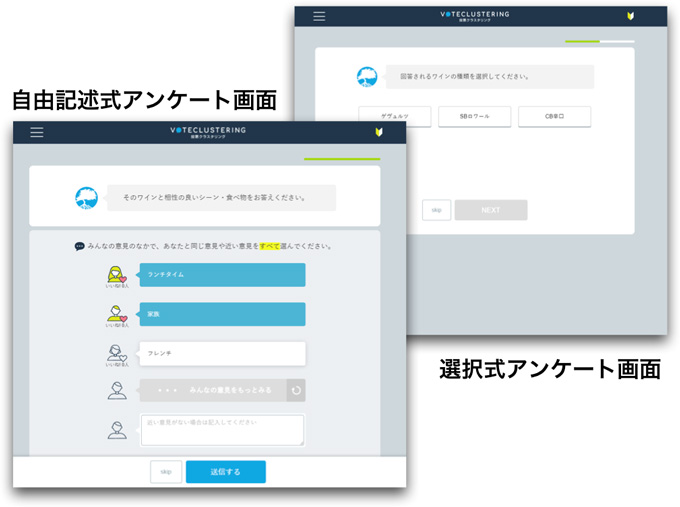 |
| 図3:回答意見の入力の様子 |
3. アンケートデータの集計技術
回答候補を提示するために、まず、ウェブアンケートシステムで得られた意見回答の集合として、回答者たちの判定(賛成するか否か)でつないだグラフ(ネットワーク)データを得る(図4)。グラフデータを、機械学習アルゴリズムの一つであるグラフ分割アルゴリズムによって処理することで、近い意見回答をまとめ上げることができる。各回答者に提示する、他人の回答の数を多くするほど、グラフ分割によって得られる意見集約結果はより精密になる。この方法を用いると、回答者からの解釈・比較結果を処理できる限り、母数が大規模なアンケートであっても多様な意見を集約できる。
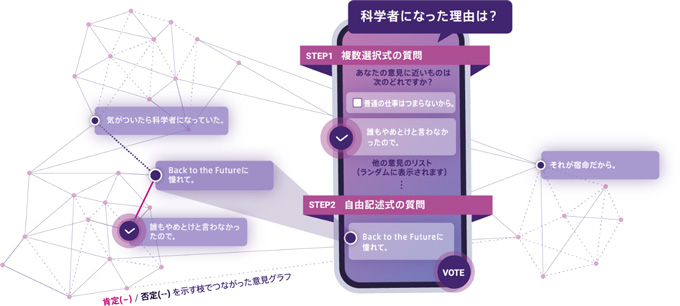 |
| 図4:回答からグラフデータを生成する様子 |
投票クラスタリングにより社会における多様な意見を抽出し、理解しやすい形で集約することは、より高いレベルの民主主義社会を実現するために非常に重要であり、さまざまな場面での活用が期待される。
今後、実証実験サイト(https://aistairc.github.io/prom-vc-ja/、図1)を通して、大規模自由記述式アンケートの機会を広く提供し、実証実験を重ねていく。投票クラスタリングで収集されたデータは、産総研でデータ解析をし、結果をアンケート利用者に提供する。これを通して、システムの有効性を検証するとともに、より高精度なデータ処理方法の研究開発を進め、実サービス化を目指す。
国立研究開発法人 産業技術総合研究所
人工知能研究センター 確率モデリング研究チーム
研究員 川本 達郎 E-mail:kawamoto.tatsuro*aist.go.jp(*を@に変更して送信下さい。)
人工知能研究センター 確率モデリング研究チーム
研究チーム長 本村 陽一 E-mail:y.motomura*aist.go.jp(*を@に変更して送信下さい。)